Data Mapping
This page explains how data mapping works in xAssets. Data mapping provides a rules-based recognition and translation system for cleaning incoming data during imports. It is most commonly used during network discovery data loads to standardise raw discovery data into consistent, usable values.
What Data Mapping Does
A data mapping record is essentially a rule that says "when this value is found, replace it with that value." For example:
- A discovered operating system string "Windows NT 5.1 (Build 2600)" is recognised as Microsoft Windows XP with manufacturer Microsoft.
- A discovered model string "HP ProLiant DL380 Gen10" is standardised to HPE ProLiant DL380 Gen10 with manufacturer Hewlett Packard Enterprise.
- An SNMP Object ID "1.3.6.1.4.1.2636.1.1.1.2.31" is mapped to manufacturer Juniper Networks, model EX2200.
The core xAssets application does not use data mapping directly in the user interface. Instead, data mapping is used by transformations that process data imports, most commonly the network discovery data loader.
Data Mapping Types
Each data mapping rule belongs to a Data Mapping Type that defines the category of recognition being performed. Data mapping types are managed from Admin > Data > Data Mapping Types:
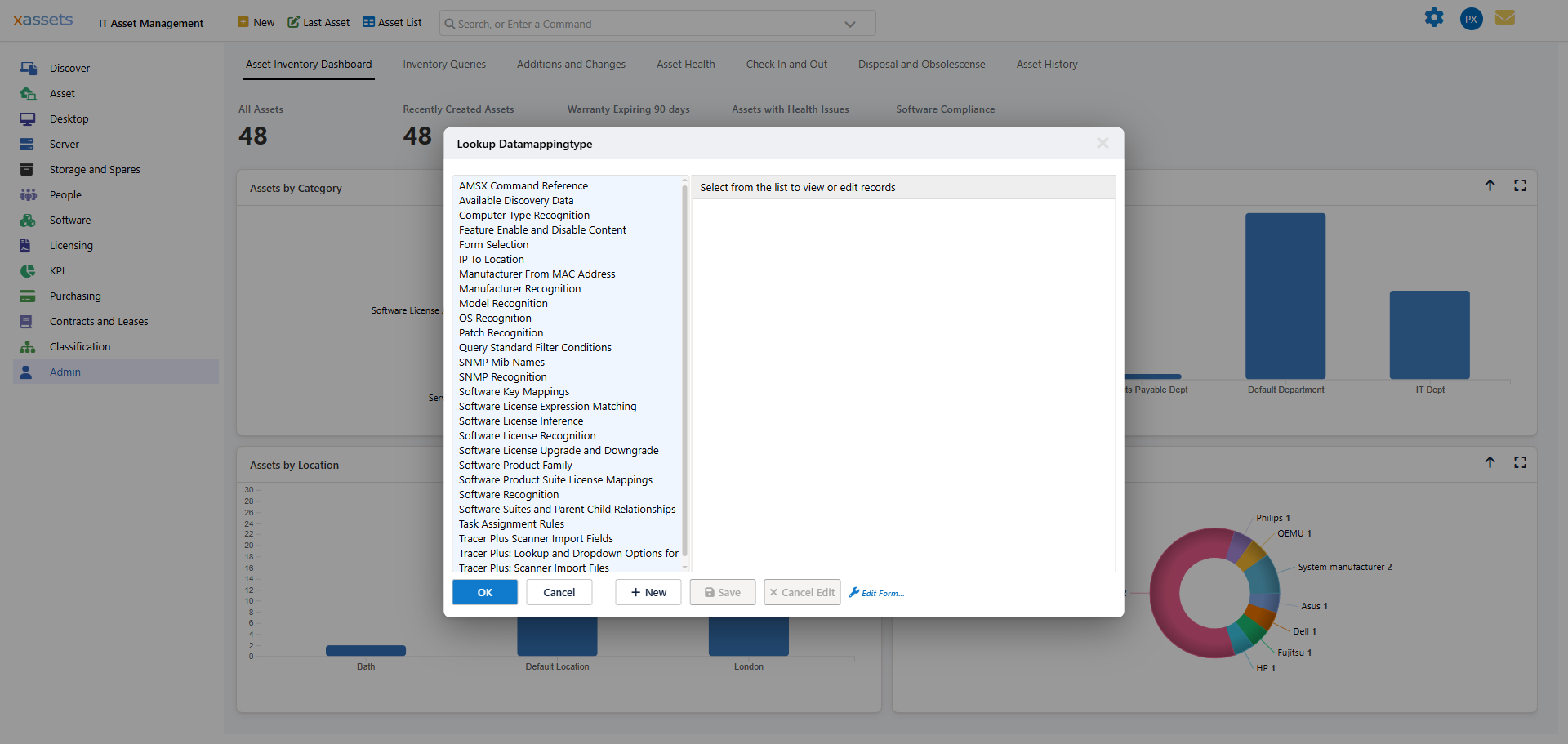
The main data mapping types used in network discovery are:
| Data Mapping Type | Purpose |
|---|---|
| Software Recognition | Translates raw software installation strings into standardised product names |
| Operating System Recognition | Maps detected OS strings to standard OS names |
| Patch Recognition | Identifies installed patches and hotfixes |
| Manufacturer and Model Recognition | Standardises hardware manufacturer and model names |
| Manufacturer from MAC Address | Identifies the manufacturer from the network adapter MAC address prefix |
| SNMP Object ID | Maps SNMP OIDs to manufacturer, model, model code, and asset category |
| Location from IP Address | Identifies the physical location based on IP address ranges |
| Custom Recognition | User-defined mapping types for other data standardisation needs |
How Data Mapping Works
Each data mapping type has a set of mapping records. Each record contains:
- Source values -- the incoming raw data to match against (supports exact and wildcard matching).
- Target values -- the standardised values to replace the source data with (e.g., manufacturer name, model name, category code).
When a transformation runs, it applies the mapping rules to the incoming data. For each field being mapped:
- The transformation reads the raw value from the source data.
- It looks for a matching rule in the data mapping table.
- If a match is found, the raw value is replaced with the target values from the rule.
- If no match is found, the raw value passes through unchanged.
Editing Data Mapping Records
The data mapping screen adapts to the data mapping type being edited. In the example below, SNMP Object IDs in the source are mapped to manufacturer, model, model code, and asset category in the target:
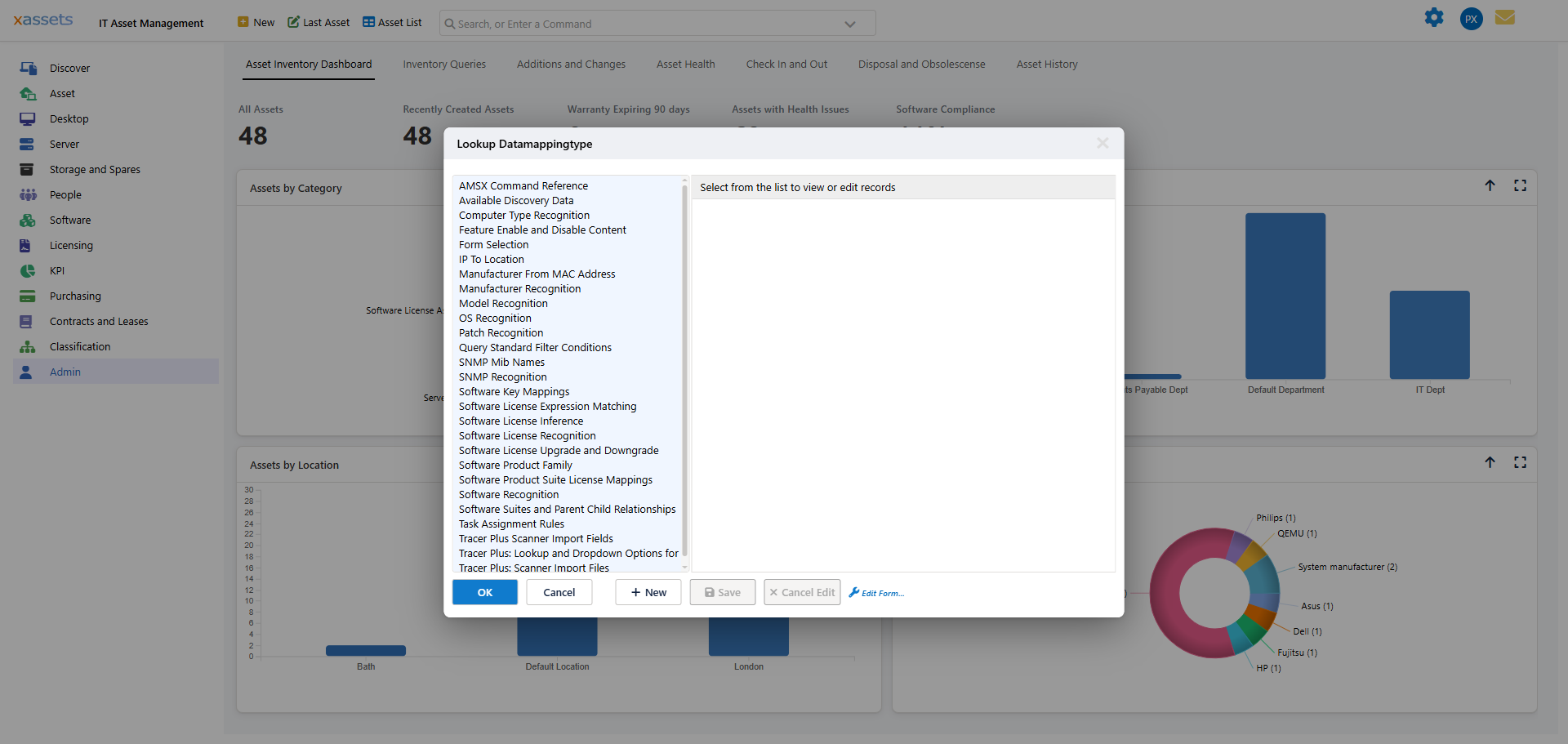
To add a new mapping record:
- Navigate to Admin > Data > Data Mapping Types.
- Select the mapping type you want to add a rule to.
- Click New or Add to create a new mapping record.
- Enter the source value(s) to match.
- Enter the target value(s) to map to.
- Save the record.
Using Data Mapping in AMSX Scripts
The AMSX scripting language supports applying data mapping rules programmatically using the ApplyDataMappingLike command. This is used in transformation scripts that load discovery data.
For example, the following AMSX command applies the "Model Recognition" data mapping type to the "NetworkDiscovery" table:
ApplyDataMappingLike "NetworkDiscovery", "Model", "SourceValue1", "Model", "TargetValue1", "Model Recognition"
This translates the value in the "SourceValue1" field into the "TargetValue1" field using the "Model Recognition" mapping rules, with "like" (wildcard) matching enabled.
Tip: When discovery loads produce unrecognised items, add new data mapping records for those items. Over time, the data mapping tables build into a comprehensive recognition library that handles most incoming data automatically.
Warning: Data mapping rules are applied during import processing, not retroactively. Adding a new mapping rule will not update records that were imported before the rule existed. To update existing records, re-run the discovery data load or manually correct the data.
Related Articles
- Integration and Data Operations with Transformations — transformations that use data mapping
- Specification Data — custom fields that may be populated via data mapping